Generative AI Is rapidly reshaping user behavior
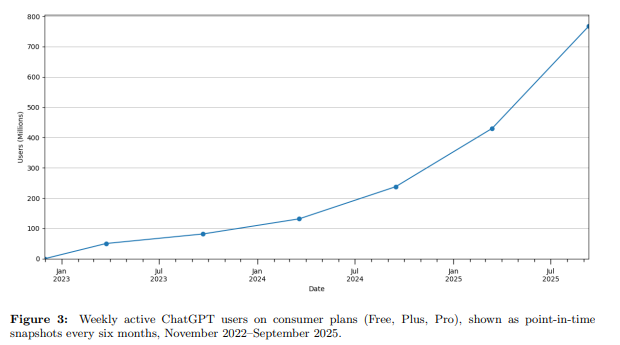
In just a few years, generative AI tools like ChatGPT have fundamentally changed how people search for and consume information. ChatGPT reached 100 million weekly active users within a year of its late-2022 launch, and surged to over 700 million by mid-2025–nearly 10% of the world’s adult population.
Meanwhile, AI-powered search features like Google’s AI Overviews and Gemini are transforming discovery across the web. Recent data shows that 8 out of 10 users now get their answers directly within search interfaces, bypassing traditional websites entirely.
These shifts are increasingly visible in usage data across scholarly platforms. Much of the disruption stems from off-platform AI tools, like ChatGPT or Perplexity, which summarize or extract content without linking back to the original source—making engagement harder to trace. In these cases, traditional metrics like sessions and item requests no longer reflect the full value scholarly databases provide, even when their content plays a central role in the research process.
In the most common use cases, researchers infrequently click through to the source—even when it’s foundational to their work. This is part of a broader pattern: in the news sector, search referral traffic fell by about one-third in a single year, largely due to AI-generated summaries reducing the need to click through.
Academic behavior moves a bit more slowly but appears to be following suit. Researchers may still be engaging deeply with JSTOR-hosted articles—just not in ways COUNTER traditionally records. As Scite’s co-founder recently posted on LinkedIn, today’s metrics are “blind to how research articles are being used with AI,” posing a growing challenge for assessing value.
Impact on scholarly databases and the cost-per-use model
These rapid shifts present new complexities for libraries and scholarly platforms alike. Traditional metrics like sessions and item requests were built to track direct user interactions, but they fall short when AI acts as an intermediary—surfacing, summarizing, or citing content without triggering a measurable, or clearly agent-initiatited, event.
Libraries have long relied on COUNTER-compliant usage data to calculate cost-per-use and inform investment in licensed resources. But in an AI-mediated research environment, that model becomes harder to interpret. A researcher may benefit significantly from an article summarized by an AI tool without ever visiting the platform.
The issue isn’t just technical—it’s conceptual. Even without AI, not all usage carries the same weight. A single retrieval might represent a fleeting glance or a critical component of a major research project, yet both are counted equally. With AI increasingly guiding researchers to key insights, the gap between measurable activity and actual impact continues to grow.
This has led to what many are calling “usage leakage” or “invisible use.” These are moments where content is central to a user’s outcome, but uncounted in traditional reporting. That disconnect risks undervaluing resources that remain core to the research process—just accessed in new ways.
How the industry is responding (COUNTER and others)
The scholarly communications community is actively responding. COUNTER—whose standards underpin library usage data reporting—has convened a generative and agentic AI working group and released draft guidance for tracking AI activity (open for community input through February 9, 2026).
One proposed change is to introduce a new usage attribute like Access_Method = Agent to distinguish AI-facilitated interactions from direct human usage. This would allow platforms like JSTOR to report how often content is accessed or cited by AI on behalf of users, ensuring libraries get credit for value delivered—even indirectly.
COUNTER’s draft acknowledges that these AI agents differ meaningfully from old-style bots. A student asking ChatGPT a question sourced from JSTOR is not the same as a web crawler, and both deserve different treatment in usage reporting. The draft also outlines how AI platforms like ChatGPT, Consensus, or Perplexity could align with existing syndicated usage recommendations to ensure that third-party interactions are traceable and reportable.
Beyond COUNTER, broader academic discussions are underway. Ithaka S+R has launched its third cohort examining AI literacy, part of a multi-year research initiative to explore the role of AI in higher education—with a focus on tools, governance, and values. Publishers and librarians alike are also testing new metrics and models of impact, exploring alternatives to cost-per-use such as measuring depth of engagement and return on educational outcomes.
JSTOR’s approach: adapting to AI-assisted workflows
At JSTOR, we’re committed to adapting in step with our community’s evolving needs. We’ve introduced a platform-native AI research tool that helps users ask questions, generate summaries, and explore academic content in a conversational way—without leaving JSTOR.
Early results suggest it’s supporting—not replacing—scholarship. Users spend more time on the platform, explore content more selectively, and report that the tool helps them understand relevance faster. Yuimi Hlasten, E-resource and Scholarly Communication Librarian at Denison University, describes how JSTOR’s AI research tool helps research more efficiently—and how tools like these can serve as equalizers, helping international students overcome language barriers and adapt to academic expectations in a new context.
All interactions are grounded in JSTOR’s trusted content and cited back to their sources, reducing the risk of hallucination and ensuring academic integrity. To help institutions understand the full picture of how content is being used, we surface these interactions in a JSTOR Engagement Report—highlighting user activity that goes beyond traditional COUNTER metrics, including use of the AI research tool, citation exports, saves to Workspace, and more.
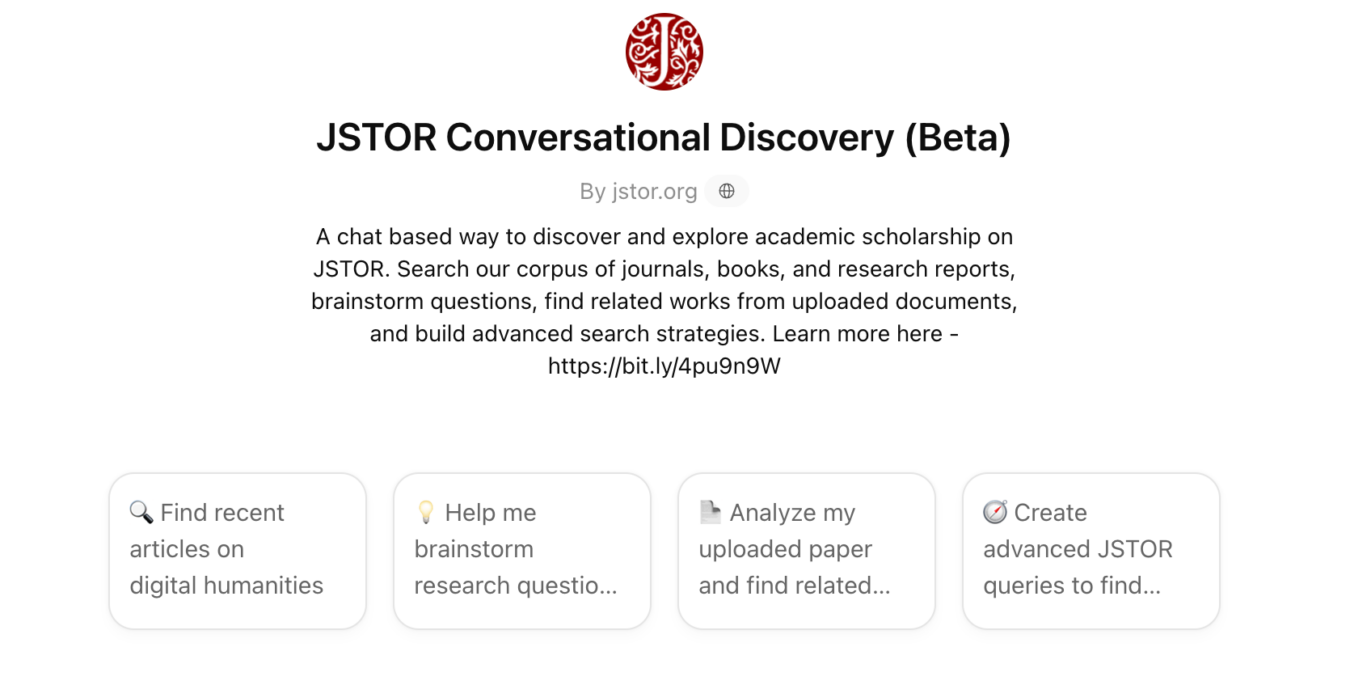
We’ve also launched JSTOR Conversational Discovery, a custom GPT accessible via OpenAI that offers a chat-based search experience and a gateway to the full text content only available through the resources licensed by their library. This aims to help bridge the gap between AI-powered discovery and trusted library resources.
At the same time, we’re contributing to the COUNTER initiative and working to ensure that emerging standards reflect real user behavior and real library value. As new AI-facilitated interactions become more directly measurable, we’ll support transparent reporting to help libraries see the full picture.
Navigating the future, together
This moment calls for collaboration and adaptation. A dip in traditional usage doesn’t mean a drop in value, especially when scholarship is increasingly shaped by AI-driven discovery.
As research behaviors continue to shift, JSTOR remains a trusted, nonprofit partner—committed to evolving alongside you while staying grounded in the academic values we share.
This moment calls for collaboration and adaptation. A dip in traditional usage doesn’t mean a drop in value, especially when scholarship is increasingly shaped by AI-driven discovery. Together, we can ensure your resources remain essential to the research experience. The community is responding with innovation and collaboration—libraries need not face this future alone. We all have a role to play in ensuring scholarly resources remain essential—and measurable—in this new environment.
In the meantime, here are three ways to be proactive:
- Stay informed and engaged with evolving standards: Engage with COUNTER as it redefines how AI-mediated usage is counted—we’re contributing too, and your voice matters. If you attend conferences—virtually or in person—look for sessions where these conversations are happening in real time.
- Re-examine what “usage” means at your institution. Begin discussing trends with stakeholders and bring context to the numbers—usage patterns may be changing, but your insight into faculty and student needs helps interpret what they really mean. A single AI-assisted content interaction might save a researcher hours of work, even if it doesn’t register as a typical session or retrieval—and that has real value. Support these use cases with data from your JSTOR Engagement Report, which surfaces activity beyond traditional COUNTER metrics, including usage of JSTOR’s on-platform AI features, citation exports, and more.
- Leverage JSTOR’s tools and share your feedback. If you haven’t already, explore the AI-enabled features now available on JSTOR for free to all participating institutions, or test our beta GPT to search JSTOR conversationally. These are built to support today’s workflows—and shaped by what we learn from you.
We’ll continue building tools, contributing to standards, and reporting impact in ways that reflect how research really happens. Thanks for partnering with us as we navigate what’s next—together.