How JSTOR helps users access the content they need, when they need it
A student opens a journal article they need for class. The PDF loads. The text is visible on screen, but their screen reader falls silent, or worse, begins reading out of order, skipping structure and rendering the document as noise rather than knowledge. The article is technically available, but not meaningfully usable.
This is the gap that accessibility work is really about: not whether content exists, but whether it works for everyone who needs it.
At JSTOR, closing this gap has meant grappling with a challenge that is both deeply technical and fundamentally human. Here’s how we approached it, what we built, and what we continue to learn.
Why this is hard
PDFs are the primary format for scholarly content, and as one of our engineers put it, they are “true messes.” A modern PDF and one created thirty years ago may share a file extension, but almost nothing else.
As Senior Software Engineer Evan David reflected during this work, “They vary wildly. You can look at the internal structure of two PDFs and not even know they’re the same format.”
At JSTOR, that variability is amplified by the scale and age of our collection, spanning materials from the 1600s, to PDFs created in JSTOR’s early years of the 1990s, to articles published last month.
Some files are high-quality digital originals; others are scans with no selectable text at all. Some are straightforward, while others are structurally complex or extremely large.
But the challenge isn’t just format—it’s what accessibility actually requires.
It’s easy to assume that if a PDF has selectable text, it’s accessible. In practice, that’s not enough. Screen readers depend on structure: headings, reading order, and properly tagged elements that allow users to meaningfully navigate a document. Without that structure, even text-rich documents can be confusing or unusable. As David noted, “I used to assume that having a text layer was enough—but without proper structure, a screen reader can still struggle to make sense of it.”
For millions of items in JSTOR’s collection, that structure didn’t exist. As a result, users encountering these files often had to initiate a remediation request process, waiting up to three days for an accessible version.
Why we see this as our responsibility
Accessible digital content has long been a legal requirement in many regions around the world. In the United States, updated ADA Title II requirements for public institutions—now expected to take effect in April 2027—have increased urgency across higher education. While evolving requirements have helped accelerate our work to further improve the usability of the content we provide, accessibility has long been part of JSTOR’s approach to quality, access, and usability, and will remain so.
JSTOR’s mission is to provide broad access to the scholarly record. Content that is technically available but functionally inaccessible for some users falls short of that mission.
There’s also no simple shortcut. With a collection spanning four centuries, and PDFs generated across three decades, prioritizing only new or frequently used content would leave meaningful gaps.
We also recognize the role we can play across the broader ecosystem. Work at JSTOR’s scale can help establish patterns others can follow, and improve accessibility beyond our own platform. This includes a responsibility not only to our users, but to the libraries who rely on us to provide content that meets or exceeds accessibility standards, and to the publishers and content providers who trust us to preserve the integrity of their materials while enhancing usability. Trust has to hold at every level, regardless of where content is created, or how it is remediated.
A different approach: accessibility on demand
From the outset, we knew that remediating our entire backfile in advance wasn’t practical. It would take an enormous amount of time and cost, and still risk missing what users actually need most.
So we asked a different question: what if accessibility could be created at the moment it’s needed?
This led us to an on-demand remediation model. When a user requests an accessible version of a document, the system generates it, stores it, and makes it available for every future user. Over time, the accessible corpus grows organically based on real usage.
An independent review by ASPIRE—Textbox Digital’s accessibility auditing framework for digital platforms—described this approach as “genuinely innovative,” noting that it addresses one of the most persistent challenges in academic platform accessibility: legacy backfiles.
To make this possible, our engineering team began with an internal hackathon exploring the landscape of PDF accessibility tools and testing approaches against the full variability of JSTOR’s corpus. From there, they built a scalable pipeline using cloud infrastructure and AI to automate processes that were once manual and time-intensive. Much of this work was built on deep expertise in how content enters and is structured within JSTOR.
Senior Software Engineer Vernelle Ellis, who develops the processes of ingesting and preparing content from providers to the platform, understands that the variability of incoming content was critical to making the system work reliably at scale. As she put it, “Everything starts with what we’re given. Content comes in with different structures, different levels of quality, different histories—and if you don’t account for that variability at ingest, nothing you build on top of it will work consistently.”
This variability is exactly what the system is designed to handle. Rather than assuming consistency, the approach accounts for a wide range of document structures and conditions, building on JSTOR’s existing ingest processes while adapting to the realities of the corpus.
What we built
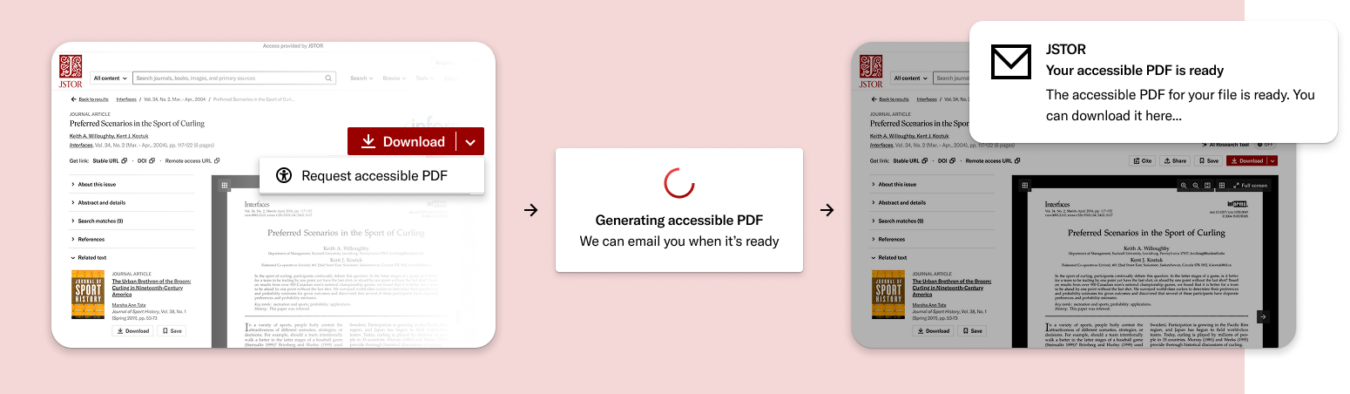
The system has two core components: accessible PDFs, and AI-generated alt text for images. Both follow the same principle: generate on first request and store for everyone.
Accessible PDFs
When a user visits an article, they now have the option to request an accessible version if one doesn’t already exist. The system then processes the document by:
- Analyzing its structure
- Generating a text layer for scanned or image-based PDFs
- Applying accessibility tags (headings, paragraphs, reading order)
These capabilities are currently available across JSTOR’s licensed content, where consistent ingest processes support reliable remediation at scale.
In most cases, accessible versions are delivered within minutes or hours rather than days. Because processing time varies based on the length, complexity, and source of the document, users can opt to be notified when it’s ready. Once created, the accessible version is available to all users. As Software Engineer Yanni Mouzakis put it, “Each time someone requests a document, it adds to a growing pool of accessible content that benefits the entire community.”
For older materials, this can be transformative. Documents that were previously only images become readable through screen readers, creating an entry point where none existed before.
AI-generated alt text for images
For images across JSTOR, including Artstor collections, users can generate descriptive alt text with a single click. The image is analyzed by a generative AI model, which produces a description that is then stored, used as alt text for assistive technologies, and made visible to all users.
While designed with accessibility in mind, this feature has broader value. Visible descriptions can help any user better understand complex or unfamiliar images, extending the benefit beyond assistive technology users. As Senior Quality Software Engineer Douglas Duford explained, “Until recently, this kind of description work always required a human. Now we can start to do it at a scale that actually meets the size of the collection.”
A purposeful use of AI
We recognize that AI in academic contexts raises important questions. Our approach for accessibility has been to apply it where most appropriate: high-volume, repetitive tasks that would otherwise be prohibitively time-consuming.
Remediation work often falls into this category. Generating structure for millions of PDFs, or descriptions for millions of images is essential, but difficult to scale through manual effort alone.
Our guiding principle has been simple: progress is better than perfect. As Dane Hillard, Associate Director of Product Engineering emphasized, “This work is about making improvements at scale, even when perfection isn’t achievable. Expanding access meaningfully, even if imperfectly, serves more people than waiting for ideal solutions at a smaller scale.”
What comes next
This work is a beginning, not an endpoint.
As the system is used, we’ll continue to learn from real-world edge cases across the full diversity of JSTOR’s corpus. We’ve also built pathways for human remediation when automated approaches aren’t sufficient, ensuring that users can request additional support when needed.
Looking ahead, we’re continuing to improve accessibility for licensed audio and video content. Transcripts and synchronized captions are already available across much of this material, providing important support for users today. We are now exploring deeper enhancements—such as audio description for visually rich video and improved workflows for reviewing and refining transcripts and captions—to better meet evolving accessibility standards.
We’re also helping institutions enhance accessibility for their own digital collections through JSTOR Digital Stewardship Services. This includes developing JSTOR Seeklight as an accessibility engine for digital archives, with support already available for transcripts of text-based materials, as well as automatically generated transcripts for audio and video content and synchronized captions for on JSTOR.
An ongoing commitment
Accessibility is not a feature we’ve added; it is part of what JSTOR is for.
Every student, researcher, and educator should be able to fully access and use scholarly content, regardless of how they interact with it. Building toward that goal will take time, iteration, and collaboration across the ecosystem.
We’ll continue to improve, learn, and share what we find along the way.
If you’d like to learn more, explore our Accessibility at JSTOR resources, and the earlier posts in this series: