When talking with library leaders, archivists, and others in the collection stewardship community about JSTOR Seeklight—the AI-powered collection processing technology in JSTOR Digital Stewardship Services—the question of bias almost always comes up. Sometimes it’s framed as: “Does JSTOR Seeklight check for bias?” Other times: “How do you avoid furthering bias with AI?”
These might sound like different questions, but they’re really two sides of the same coin. They both acknowledge a truth anyone in archives knows well: bias is inherent to description. But, as those in the field also know, description can and should be iterative—shaped and reshaped over time through revision and repair.
Addressing bias is an ongoing process, one we must engage in actively in both human- and AI-generated metadata.
In this post, I’ll share how we’re building and evolving JSTOR Seeklight’s safeguards against bias and harmful content. It’s early work, but important—and our approach reflects our values, our engineering ethos, and our commitment to transparency.
Why bias in metadata matters
Metadata shapes how collections are found, interpreted, and remembered – and it’s never entirely neutral. Human-created description has always reflected choices: what to include, what to omit, and how to frame it. Those choices can perpetuate exclusion or erasure, especially for collections from historically marginalized communities. Under-description, misclassification, or absence from catalogs can compound inequities over time. This is something my colleague Emilie Hardman (Research Lead, Archives & Special Collections, and Sr. Curator, Reveal Digital) has discussed elsewhere and surfaced in her research as a common concern in the contemporary archival field.
AI can, of course, replicate and even amplify existing biases embedded in source data or training sets. But it can also be used to detect bias, surface overlooked connections, and give human reviewers a stronger starting point for mitigating harm at scale.
This is the juncture we find most ripe for possibility—paired with productive caution.
Our multilayered approach
Technology is moving at a remarkable pace; meanwhile, metadata best practices and approaches to sensitive description continue to evolve as well. Rather than relying on a single or static approach to mitigate bias, we have developed a layered, evolving strategy that incorporates technical, procedural, and human-centered safeguards. These protect against harm while also giving us visibility into where our systems—and our human processes—need improvement.
Because the technology moves quickly, so must our methods. This means our approach is always evolving, which is a good thing. What follows reflects the three layers of our current approach, but, as I’ll cover later, we’ll continue to iterate on it alongside our community.
1. System-level evaluation using LLM-as-a-judge
First, we regularly evaluate our systems for the likelihood that they could produce bias or harmful content. This is done by processing our growing set of internal ground-truth data—collections we know well—through our large language model (LLM) provider. Then, we bring in a second LLM, separately configured, to evaluate that metadata for four critical metrics:
- Toxicity
- Inclusivity
- Neutrality
- Historical sensitivity
This technique, referred to in AI research as “LLM-as-a-judge,” lets us systematically score the likelihood of bias or harmful content, even before users engage with the system. The output isn’t just pass/fail; we document score distributions, track trends over time, and begin identifying thresholds where human intervention may be warranted.
It’s not perfect—all LLMs have their own inherent biases, trained as they are on data that contains bias—but it’s a crucial foundation for understanding ever-evolving system behavior in a rigorous, data-informed way.
2. In-product feedback from users
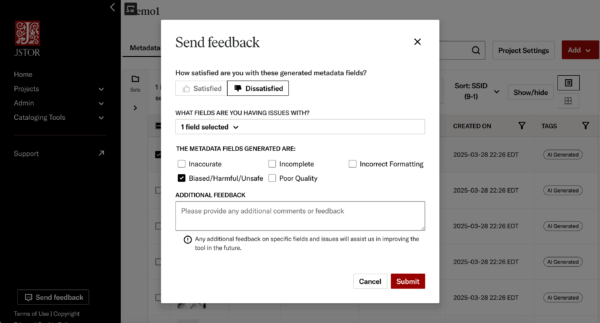
Automated evaluation isn’t enough on its own. Metadata quality can be highly contextual and subjective, especially around bias and harm. That’s why JSTOR Seeklight includes a simple but powerful tool for users to flag fields they find problematic.
Users can quickly mark a JSTOR Seeklight-generated field as “dissatisfactory,” select reasons such as bias or unsafe content, and provide additional comments if needed. These signals are routed directly to our product and engineering teams and aggregated to identify systemic issues or emerging concerns.
We know that empowering users to speak up is one of the most effective ways to catch edge cases, nuance, and lived experiences that system-level metrics might miss, which is why we’ve made it as convenient and integrated into their workflows as possible.
3. Subject matter expert review
Lastly, our internal subject matter experts—who bring deep knowledge of archival labor, metadata standards, and sociotechnical risks—regularly review our strategy and outputs. This helps ensure that our technical work aligns with our human-centered goals and ethical commitments, and provides clear guidance on which metrics to track, and how to act on user feedback. This group of internal experts will work alongside community-based working groups and industry leaders to stay abreast of changing policy and market dynamics.
Why it’s still early days—and why that’s okay
Currently, the automated bias evaluation described above isn’t applied to metadata generated by practitioners using JSTOR Seeklight, only to internal datasets and model configurations. This is deliberate. We want to refine our approach, understand our confidence levels, and ensure responsible implementation before expanding to production metadata review at scale.
But we are laying the groundwork. Our engineering team is already exploring ways to trace LLM calls more granularly, which could eventually allow us to run real-time or retrospective evaluations on institution-level metadata samples—and, importantly, do so without compromising user privacy or autonomy.
In parallel, as part of the JSTOR Digital Stewardship Services charter program, dedicated working groups are beginning to explore key questions in the future of responsible, AI-powered stewardship. One future working group will focus on the kinds of metadata review workflows that would be most meaningful and welcome. Again, this isn’t exclusively an issue that can be solved once and for all on the back end through the creative use of new technology, but rather one that will require ongoing, collaborative work that supports the evolving needs of the community, while remaining attuned to rapid technological developments.
Transparency as a feature, not a risk
We’re committed to talking openly about both what we can do today and what we can’t yet. The truth is, we’re still learning—and, importantly, we’re learning in collaboration with our community. That includes acknowledging limitations, being clear about system behavior, and building tools that allow users—not just engineers—to shape outcomes.
The AI landscape is evolving quickly. So are the expectations of library leaders, collection stewards, researchers, educators, and all other members of our community.
By starting with integrity, we aim to meet those expectations with innovation, humility, and purpose.
What’s next
We’ll continue evaluating new models as they become available, refining our scoring rubrics, and exploring deeper integrations with user feedback systems. As always, we’ll be guided by our partners across the archival field and by our aim to build JSTOR Seeklight as a technology centered on collaboration—between AI and archivists, engineering and ethics, and what’s possible today and what’s necessary tomorrow.
If you’re interested in helping shape this work—or want to learn more about how JSTOR Seeklight supports responsible metadata generation at scale—we’d love to connect.