Beyond description: Introducing transcript generation in JSTOR Seeklight
Since we first began developing JSTOR Seeklight, we’ve seen it as something of a gateway: an entry point to a broader reimagining of distinctive collection stewardship. Developed with and for archivists and librarians as part of JSTOR Digital Stewardship Services, it brings AI-powered tools into workflows long constrained by technological limits, capacity ceilings, and the constant influx of new materials. Description—including both item-level metadata and project-level insights—was the first step toward that vision, and one we’re incredibly proud to be making meaningful contributions toward. But it was never meant to be the final stop.
Now, with the launch of transcript generation for text-based items, we’re taking another big step forward, moving beyond description into broader collection processing support. This milestone signals a meaningful shift toward expanded discoverability, accessibility, and impact for the unique collections that our community stewards. In this blog post, I’ll share why transcripts matter, how we developed this capability in collaboration with practitioners, and why we see it as a turning point in the work of collection processing.
Why transcripts matter
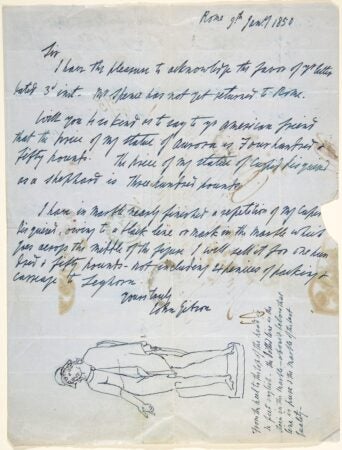
John Gibson. Letter to John Udny for Henry Farnum, January 9, 1850. The Metropolitan Museum of Art.
We started with descriptive metadata because it’s foundational to discovery. It provides structured context—like subjects, dates, people, and formats—that help connect researchers with relevant content. Transcripts, on the other hand, capture the exact words a document contains. That means full-text search, the potential surfacing of terms and themes not reflected in metadata, and more granular retrieval—down to individual names, phrases, or passages.
Together, metadata and transcripts create a full spectrum of visibility, making every word in a collection findable and usable.
With JSTOR Seeklight, institutions can generate accurate, editable, and downloadable text from typed, handwritten, and mixed-media materials. The benefits are immediate and powerful:
- Discoverability: Every word becomes machine-readable, enabling deeper search and indexing, and laying the groundwork for full-text discovery in JSTOR search.
- Accessibility: Transcripts offer legible alternatives to handwritten and degraded texts, as well as machine-readable alternatives for text of any type, helping institutions meet accessibility requirements (including the April 2026 federal web content mandate for higher education), and support equitable access.
- Integrity with oversight: As with metadata, the expert remains in control. Transcripts can be reviewed, edited, or replaced via an integrated editor or offline workflows to preserve professional standards and institutional control.
In short, transcripts turn static scans into discoverable, accessible digital assets without sacrificing professional or institutional standards.
A powerful new approach to transcription
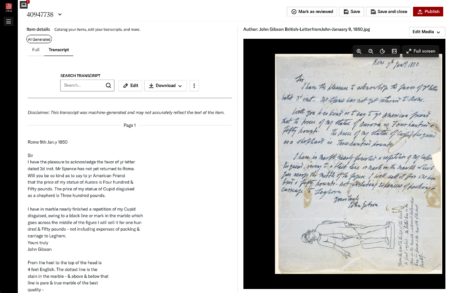
To simply call this “transcription” somewhat undercuts what’s happening behind the scenes.
Traditional optical character recognition (OCR) has long enabled text extraction from typewritten materials, but it struggles with handwritten content. Handwritten text recognition (HTR) technologies improved on OCR, but even these legacy systems struggled with variation in style, quality, or language.
JSTOR Seeklight moves beyond the limitations of previous approaches, combining next-generation HTR with large language models (LLMs), a technical advancement that delivers high-quality results, even on 19th-century cursive, or pages marred by bleed-through or marginalia.
Built with the community
Just as we did for our initial metadata generation functionality, we pursued transcripts as the next big feature for JSTOR Seeklight because we heard it’s what the community needed most. One of the first questions we’d hear after introducing metadata generation to collection stewards was: What about transcripts?
Earlier this year, we ran extensive testing with librarians, archivists, and digital collection specialists, from early concept reviews to usability tests on our prototypes. Their feedback helped shape every aspect of what we’re launching. Here’s what we heard, and how JSTOR Seeklight addresses it:
- Manual transcription is slow and resource-intensive.
- JSTOR Seeklight generates transcripts in seconds, reducing the time and cost of preparing collections for access and reuse.
- Many users—especially students—can’t read cursive.
- JSTOR Seeklight makes handwritten, typed, and mixed-format documents readable for everyone, which expands access to primary sources.
- Handwritten and historical items were often deprioritized for processing.
- By removing a key bottleneck, JSTOR Seeklight supports the reprioritization of these vital materials.
- Documents are often damaged or complex.
- JSTOR Seeklight performs well in extracting meaning—even from materials with bleed-through, marginalia, and/or discoloration—bringing new life to aging or damaged content.
- Metadata alone can’t capture everything.
- With transcripts, every name, date, phrase, and passage becomes searchable, which helps to surface content that structured metadata alone might miss.
- Teams need flexible editorial workflows.
- With support for line-by-line review, editable and downloadable transcripts, and the ability to upload or regenerate text, JSTOR Seeklight makes it easy for teams of staff, students, and/or volunteers to collaborate.
This is what true community-driven design looks like: working together to build tools that are practical, responsive, and purpose-built for real-world stewardship work.
What’s next
Just as full-text search of journals on JSTOR transformed scholarship decades ago, we believe JSTOR Seeklight transcripts have the potential to transform the discoverability and impact of archival and special collections today.
As transcripts roll out, we’re eager to see how our creative and resourceful community puts them to use—to expand access, meet accessibility requirements, and reimagine what’s possible in stewardship work. We look forward to continuing to partner with collection stewards to shape what comes next.
Learn more
Transcript generation is available today for all Tier 3 participants in JSTOR Digital Stewardship Services. Interested in exploring AI-assisted stewardship and shaping future developments? Learn more about our charter program and how to get involved.
About the author

Syed Amaanullah is a Senior Product Manager at ITHAKA, where he leads the strategic product development of AI-driven solutions within JSTOR Digital Stewardship Services. With over 12 years of experience in leading teams and building innovative ed-tech products, he has deep expertise in leveraging the capabilities of technology to drive meaningful outcomes for the academic community. He is proud to help advance ITHAKA’s mission to expand access to knowledge and education.